-
How to: Backup iMessages using OSX and Google Drive
This is pretty short but I wanted to leave it here for posterity. The process is to just add the archive folder to Google Drive. You don’t have to move it to your Google Drive folder or hard link, as other tutorials have suggested, just add it to the list of extra folders synced by Google Drive.
First, find the folder iMessages uses to store all its data. Mine is in
/Users/soph/Library/Messages. If you aren’t able to see the Library folder, usecmd-shift-.to make hidden items viewable.Select the Google Backup and Sync icon in your menu bar at the top of your screen. Go to …->Preferences->Choose Folder and select that folder.
And, there, you’re done!
-
A Case for Diversity
Author’s note: This is a pre-publication draft. Parts of this material may appear in subsequent publications. I’m sharing in this format to enable transparency and dialogue but I do not wish to misrepresent the relationship this draft may have with any later work.
There’s a lot of talk of diversity, especially discussion of the reasons companies and other groups should prioritize diversity.
Diversity for fairness
One important idea is a general sense of fairness. Careers that pay well should be distributed roughly proportionately among genders, ethnic groups, and other ways of categorizing people. We have the sense that there’s nothing about being male that makes someone a better programmer, or about being white that makes someone a better hedge fund manager. Then fairness suggests to many that, any unevenness in who gets access to these desirable careers reflects a lack of fairness. When a tech company primarily is located in a country where black people make up 12% of the population, but that company’s tech workers are only 1% black (as is true of Alphabet/Google, Amazon, and other tech companies) then something unfair is going on. Sure, there is some buck-passing here. There are problems at many levels that create unfairness: geographic segregation, school systems, gaps in generational wealth accumulation, gaps in laws. But the culture of many of these tech companies is one that famously fights (and wins!) against structural hurdles like these. If these companies can move fast and break things when it comes to new features and their bottom line, we should expect the same when it comes to fairness.
Diversity for social tech
There are other reasons companies prioritize diversity, like legal ones, that I won’t get into. Instead I want to focus on something I would like to hear more often and more clearly from the technology world. Independent of everything else, diversity will become essential to the success of any tech company. This is because the products made by tech companies are increasingly cultural ones, embedded in our everyday social lives, and producing social products that are successful requires engineers/designers/etc. who have a social understanding of those who use the products.
Let’s not forget when Google Maps pronounced Malcolm X Street “Malcolm the Tenth” as if he were a british monarch[Baratunde Thurston]; that Facebook’s name policy locks the accounts of trans and gender non-conforming users, including a Facebook employee[Zoe Cat]; when Google Images automatically labeled black people gorillas[Jacky Alciné]; the long history of racial and gender bias in face recognition[Joy Buolamwini: Gender Shades]; the many cases of technology ignoring dark skin [like soap dispensers and heart rate monitors]. These are just a few examples but they illustrate the point that we are interacting with our technology in social ways. Each of the above examples would have been trivial to catch for an engineer, project manager, or other employee from an underrepresented group.
What I’m arguing here is that it’s in tech company’s self-interest to seriously prioritize diversity. Even a company that is unconvinced that diversity is important because of fairness or legal reasons should be concerned about how they plan to design products that people interact with in social contexts. These companies will want to ensure that their tech workforce is diverse at every levelâfrom the people writing the code to those deciding which new features to develop and beyondâbecause each of these decisions will become more significantly social as time goes on.
Diversity to stop algorithmic violence
One specific concern involves the idea of algorithmic violence[Mimi Onuoha], a term coined by Mimi Onuoha that refers to the ways that automated decision-making does real harm to people. In college I studied Computer Engineering and took an ethics course along with civil and mechanical engineers where we discussed the ethical challenges involved in designing walkways and other physical things. What was missing then, and seems to largely be missing now, is a serious look at how decisions made in technology companies, including by software developers and data scientists, lead to real consequences.
Some algorithmic violence is quite easy to see, such as when Palantir (one of the most valuable data companies and one that was recently sued for racial discrimination[Vanity Fair]) builds an enormous data machine for the targeting and tracking of immigrants for deportation[The Intercept]. In most cases, though, algorithmic violence is less than obvious. Guillaume Chaslot writes[Medium] that YouTube’s massive recommendation engine, one that he helped design, is tasked with maximizing users’ viewing time. The recommendation engine does this in a single-minded way that ignores the effects that the kind of content one cannot turn away from (like disturbing videos targeted at kids[Medium] and conspiracy theories[Vanity Fair]) might have on its viewers and even elections[Chaslot @ Medium]. In ‘Automating Inequality’[Strand] Virginia Eubanks provides an extensive catalogue of ways that seemingly âobjective’ automated systems harm vulnerable people, whether they were set up to do so intentionally or not.
Algorithmic violence is a problem, like information security and global warming, that is virtually guaranteed to become more important with time. Because the effects of algorithmic violence are often hidden except to those who are affected by it, companies without a diverse workforce will be at a disadvantage when trying to recognize and prevent such violence. So prioritizing diversity is one of the many steps, like a Hippocratic oath for technology[Marie], we need to take to counter algorithmic violence.
Recommended readings:
- Weapons of Math Destruction by Cathy O’Neil - [Strand link to purchase] (http://www.strandbooks.com/political-science/weapons-of-math-destruction-how-big-data-increases-inequality-and-threatens-democracy-0553418831/)
- Automating Inequality by Virginia Eubanks - [Strand link to purchase] (http://www.strandbooks.com/sociology/automating-inequality-how-high-tech-tools-profile-police-and-punish-the-poor/)
- On Algorithmic Violence by Mimi Onuoha - [github link] (https://github.com/MimiOnuoha/On-Algorithmic-Violence)
- Gender Shades, research project led by Joy Buolamwini - 2018 paper by Buolamwini and Gebru
-
Soph's VM tweaks
What’s this
(hi, this is a test)
This is a scratch pad for me to use when I set up new virtual machines. I’m sharing it in case anyone else is interested.
fish is by far my favorite shell
Install it and configure it following this tutorial
omfis a handy package manager for fish.I use the foreign environment interface to load my
~/.bash_profileand similar. (Thank you)You can install themes with it and my fav is probably
sushi.If you’re using anaconda, you’ll have to remember to use
activateinstead ofsource activatedetails.tmux
I love tmux! I p much always install it first thing. To make it more useful, I add options by creating the following file at
~/.tmux.conf.set-option -g mouse on set-option -g default-command /usr/bin/fishother tools
Access Jupyter from your server
I typically set up a jupyter server mostly according to Chris Albon’s instructions here.
Start Jupyter on restart
Previously, my workflow was something like this: go to console in browser and start ec2, go to terminal and mosh into ec2, start jupyter notebook, go back to browser and use jupyter. That’s an annoying amount of steps. I like to simplify this so that on every device restart, my machine automagically starts a jupyter notebook server and glances (which I use to monitor the machine’s resource usage).
Here’s the solution I found, which is a modification of this. Modify your
/etc/rc.localto include the following above theexit 0line:export PATH="$PATH:/home/ubuntu/miniconda3/bin" nohup jupyter notebook --notebook-dir=/home/ubuntu/ & nohup glances -w & exit 0 -
Paperspace how-to (cheap cloud GPU)
The use of GPUs have become quite important for applications of Deep Learning. The landscape of this hardware has lately become quite interesting. The cryptocurrency fad has led to GPUs becoming expensive and/or unavailable. One solution to this problem is to rent a computer with a GPU from Google, Amazon, Microsoft, and others. Google even recently lowered their GPU prices quite substantially. I’ll save doing a full comparison of each platform for later, but what I’ll go over today is getting started with a relatively new service, PaperSpace based in my home of Brooklyn <3.
The virtue of paperspace is that their entry-level GPU offering costs $0.40/hr (compared to Google’s new $0.45/hr and Amazon’s $0.90/hr) but benchmarks ahead of Amazon and other offers based on the Tesla K80.
Below, I’ll show you how to get up and running quickly and how to set up cost-saving measures, like auto-shutdown.
Steps to get running
First, as with any new machine, update the current packages with
sudo apt update sudo apt upgrade(Note: I had to add the
--fix-missingflag tosudo apt update)Add a new user according to these instructions.
open ports with ufw
By default, Paperspace has a very strict firewall (this is a good thing). We’re going to want to get to our jupyter notebooks, though, so we need to open up some ports. You can do that with these instructions.
My version is pretty unsafe (it allows access from any IP) so feel free to check that link for info on restricting the IP that can access your jupyter port.
sudo ufw allow 8888 sudo ufw allow 60000:61000/udpset up jupyter
fix autoshutdown with ssh
https://paperspace.zendesk.com/hc/en-us/articles/115002807447-How-do-I-use-Auto-Shutdown-on-my-Linux-machine-when-connecting-through-SSH-
set up ssh keys
https://www.digitalocean.com/community/tutorials/how-to-set-up-ssh-keys–2
https://apple.stackexchange.com/questions/48502/how-can-i-permanently-add-my-ssh-private-key-to-keychain-so-it-is-automatically
Install cuda 9.1
You can use the official guide but I prefer these instructions.
Install cudnn
http://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html
-
Deep Learning Tips
I often find myself in roughly this situation:
I’ve done a lot of work to pre-process data, researched different DL architectures and selected one (or more), modified it so that it works well on my data. And now I’ve got a model that does well, but not quite as well as I want it to.
Below I’ll outline steps that I find very useful in this situation. Of course, more detail about how to get to that point is for another post. Also, I’m using Keras so many of these are specific to that tool, but they could absolutely be applied to other DL packages.
Clean up training code and improve logging.
My typical workflow when I’m building or tweaking a model by hand is to run Kears in a Jupyter notebook. This works fine if the entire pipeline runs in a few minutes but doesn’t work if I need to close my laptop while the pipeline is running. Jupyter often has trouble gracefully reconnecting and then I lose all the
verboseinfo.Porting my code into a self-contained python script allows me to connect to a machine over mosh and tmux, run the script, and then forget about it. This is handy on it’s own but it’ll be extremely handy when we get to the later tips.
The tools I use for this are:
keras.callbacks.CSVLogger(...)keras.callbacks.TensorBoard(...)keras.callbacks.ModelCheckpoint(..., save_best_only=True)
CSVLoggertakes the output from verbose and stores it in a csv file for later. If you’re using tmux, it should be preserving your terminal log (and theverboseoutput) but csv puts all of that history data in a format where you can easily use it.TensorBoardis super handy if you want to be able to monitor the progress of a long-running model from somewhere other than your terminal. I can access this from my iPad and it looks great!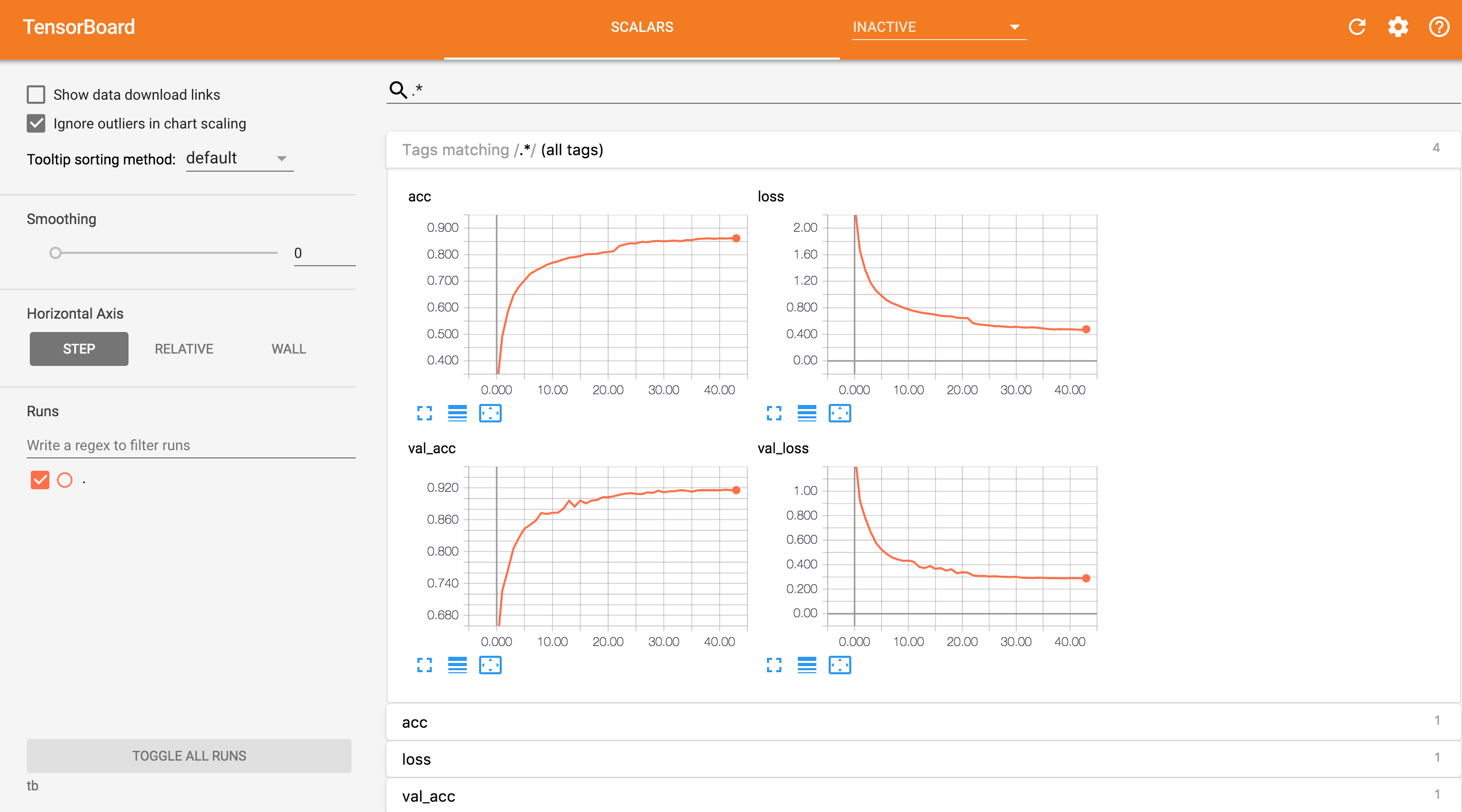
ModelCheckpointsaves your model every so often (you set the frequency as a parameter). This is nice on its own because it allows you to access a model that was trained in a script from anywhere (including my preferred tinkering environment, Jupyter). Even more than that, if you usesave_best_only=True, then the script is automatically saving space by only saving the best performing model (you should youseval_lossor some other validation metric with this option).Learning Rate Schedule
keras.callbacks.LearningRateSchedulerkeras.callbacks.ReduceLROnPlateauThis is my preference. I use this in conjunction with EarlyStopping and ModelCheckpoint all the time.
Use noise and other transformations to enlarge your datasets
- keras.preprocessing.image.ImageDataGenerator()
- Tensorflow blog discussing this with background noise
Optimize
There are many hyperparameters that can be optimized:
- Learning rate
- Dropout rate
- Preprocessing steps
- Different architectures (size and shape of layers as well as count) and parameters
- Regularizers and parameters
- Initializers and parameters
- and more!
These create an enormous space of possible models for which to test. My recommendation is to find something that works and then from that functioning model determine plausible options for the above hyperparameters. Then throw what you have into hyperopt.
- HyperOpt does this automatically. It’s poorly documented but fairly easy to use.