-
How to make a gif in Colab
I wrote a little demo of how to make a gif in Colab. You can check it out below or you can open it and run it yourself by clicking on the “Open in Colab” button at the top.
-
Neat papers in ML and DS: Dec 2018
- ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness
- Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet
NeurIPS
- Are GANs Created Equal? A Large-Scale Study
- An intriguing failing of convolutional neural networks and the CoordConv solution
- On the Dimensionality of Word Embedding
- Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
- Bias and Generalization in Deep Generative Models: An Empirical Study
- How Does Batch Normalization Help Optimization?
- Training Deep Models Faster with Robust, Approximate Importance Sampling
- DropMax: Adaptive Variational Softmax
- Relational recurrent neural networks
- Neural Arithmetic Logic Units
-
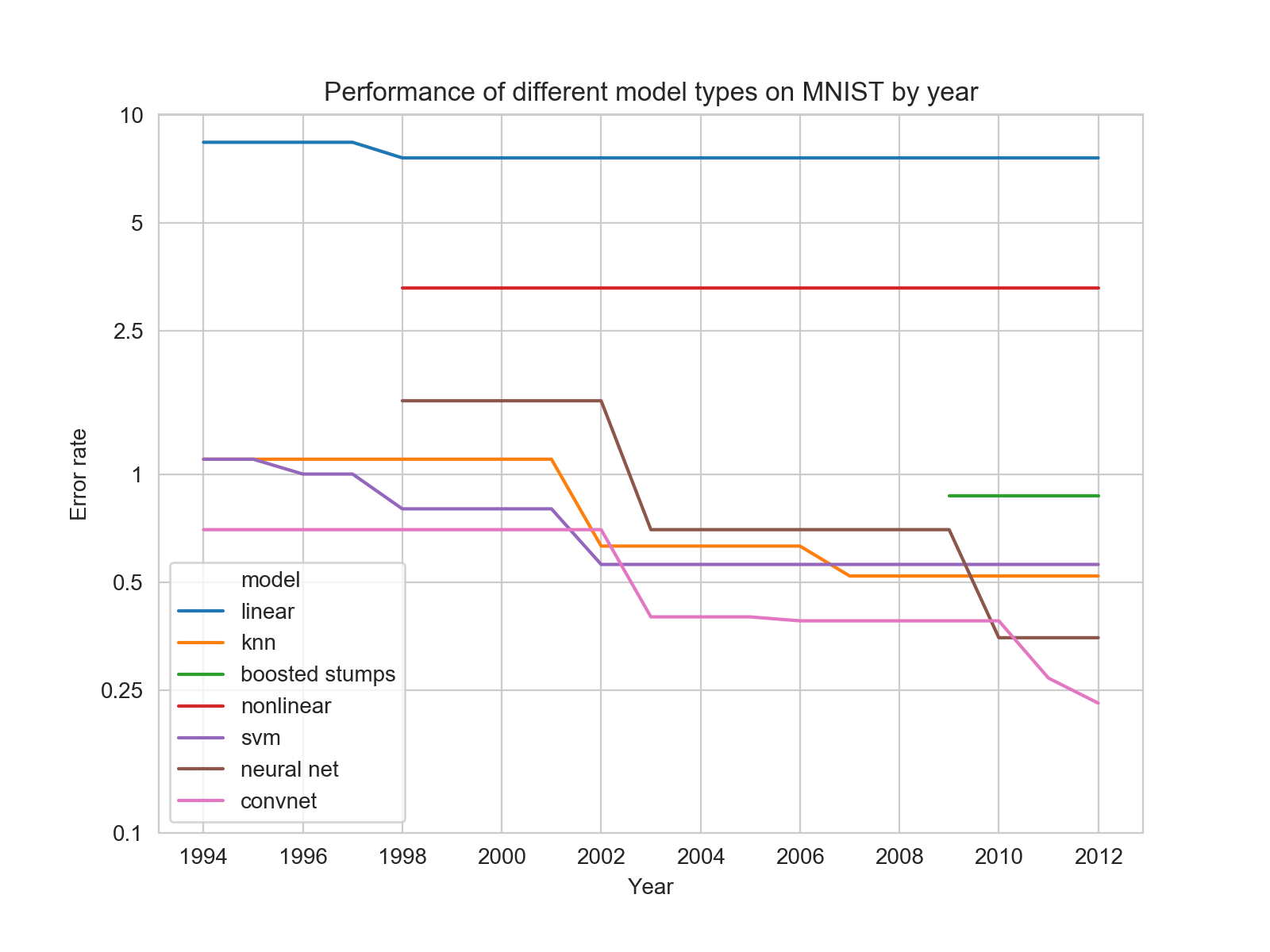
Performance of different model types on MNIST by year
Today I was trying to answer the question of why it seems like so much attention was given to support vector machines in the past. I had assumed that before the Deep Learning renaissance in 2006, SVMs were the dominate model because they outperformed Deep Learning models of the time. But if that was true, I wanted to see how it changed over time and how SVMs and DL models compared to less practical models like KNN.
To investigate this, I went to a table of top performances on the MNIST dataset maintained by Yann LeCun. This table is helpfully organized by model type and year.
I made a bunch of hand modifications (which you can find here) to allow me to plot the performance of different model types. To my surprise, SVMs were actually never the dominant. The reasons SVMs were favored over Deep Learning turn out to be much more subtle and I’ll save them for later.
-
How to clean Apple's butterfly keys with a metrocard
In early 2015, Apple debuted their butterfly keyboard on their new “macbook”. Since then Apple has migrated this “feature” to their macbook pro line while several have voiced loud complaints about the shallow, fragile keyboard. Apple has since admitted that there’s a problem and offered to repair keyboards with sticky or unresponsive keys.
But turning your computer in for a repair is tedious and likely requires parting with your computer for a week or more. Also, perhaps you are like me and have already extensively repaired your unrepairable computer and violated the warranty in a number of ways. In these cases, it might make more sense to repair your keyboard on your own.
I’ve been using this dumb keyboard for 3.5 years now (what can I say, I love the romance of having the smallest possible computer that can do the things I need). I’ve cleaned these keys more times than I can count and I’ll document my process here. I know this process works for gen 1 and gen 2 of the butterfly keyboard and I’m guessing it works for the rest.
What you’ll need
- A metrocard or similar flimsy card.
- A q-tips/cloth/paper towel to clean out the keyhole.
Step 1: Remove the key cap and switch
 The back of the 'U' key cap and butterfly switch. I've marked the 4 points where the key cap connects to the switch. Sorry my potato phone stinks at macros!
The back of the 'U' key cap and butterfly switch. I've marked the 4 points where the key cap connects to the switch. Sorry my potato phone stinks at macros!
Before you do anything, make sure you understand how the key cap and switch connect to each other. The key cap is what I’m calling the black piece with the key printed on int. The switch is what I’m calling the gray-white mechanism inside the keycap that flaps its wings like a butterfly.
There are four points that connect the key cap and switch: two clips on the top and two hooks on the bottom.
When removing the key cap from the keyboard, it is very important that you only lift from the top, where the clips are. The hooks should only be disconnected after the clips have. If you get this wrong, you can break the hooks on the bottom of the key cap or the pins on the bottom of the switch. Trust me, I’ve done this!
Now, first thing you’ll do is insert one of the corners of your key cap removal tool (metrocard) under the top of the key and pry it up. (video of this below) Sometimes you’ll get both the key cap and switch together, sometimes the key cap will come loose first. The switch is held in by four little pins on the inner rim and you can easily remove it with a fingernail or your key cap removal tool.
Step 2: Clean up your mess
Remove whatever it is you got under there. It can be really small! Take your time here. I’ve typically used a damp cloth to do this but I also have a high tolerance for risk so you do you.
Step 3: Replace the switch and key cap
For this step, a similar word of caution to step 1. It is very important that you don’t squish the hooks in the key cap onto the pins of the switch
- If you haven’t already, remove the switch from the key cap.
- Insert the switch itself (so, not the key cap) into the key hole. The side of the switch that should face the computer bulges out a bit, while the top should be relatively flat. You’ll press down on the switch until the pins click into the plastic brace.
- Start with the bottom of the key cap. Slide the hooks over the pins on the bottom of the switch and then lay the key cap on top of the switch.
- You should be able to gently press on the key and hear the top two clips engage.
I have a video of these steps below.
-
Bootcamp Guide for Everyone Else
note 8/15: this is still a work in progress so check back as I fill it in
I’ve been a bootcamp instructor at Metis for about a year now1. It’s been an incredible, rewarding experience and I plan to stick around for a while. In that time, I’ve been asked a lot about bootcamps. People want to know how bootcamps work, if bootcamps are right for them, holy cow are they really $15,000? I’m putting this guide together to answer those questions.
This guide is for anyone interested in moving to a technical career, like coding, data science, or similar and are able to participate in an immersive (roughly 3 months of full time work) bootcamp. I especially intend this for people who aren’t already familiar with the tech/coding world and who don’t have ~$15,000 laying around to drop on a bootcamp.
My TLDR:
- Bootcamps are for real. They can be a legitimately great way to start a good career that too few people have access to.
- First, make sure joining an bootcamp is right for you.
- Are you likely to finish and likely to be fully committed to the job search after finishing? Be very honest with yourself about this.
- A great way to figure this out is to complete a bootcamp prep program (many are free). Bootcamp prep is also a great way to figure out which type of bootcamp (like coding vs data science) is right for you.
- Don’t put too much pressure on getting in and plan to get rejected from your first bootcamp. Bootcamps can be selective and admissions necessarily involves chance. You’ll learn each time you interview. You might have a favorite bootcamp but there are many good ones. Most bootcamps allow you to interview again later if you are rejected.
- Don’t let cost be an issue.
- Any decent bootcamp will work with you on payment if you are admitted. They’ll walk you through alternative payment options.
- If cost is a problem, consider bootcamps with alternative payment options like deferred tuition (you aren’t required to make payments until you get a job) or income sharing (your payment is comes as a percentage of your salary once you get hired). Beware that there’s typically a lot of fine print for both of these.
- Bootcamp loans can also be a great option.
What is a bootcamp?
I’m going to talk specifically about immersive tech/coding bootcamps. Still, it’s a big category. Bootcamps are also called “accelerated learning programs”; they teach technical skills primarily to people who are new. Most bootcamps are roughly 12 weeks long and in that time they are intended to prepare someone to get their first job in an entirely new field.
Let’s stop here and just appreciate how tall of an order that is. If someone wants to prepare for an entirely new career, they might go to a 4 year college or get masters degree (2+ years with low graduation rates). These bootcamps try to accomplish the same thing in 3 months for a much, much lower cost.
That’s an extremely tall order, but for those who get into and complete bootcamps, it tends to work: Course Report found that in 2017 “80% of graduates surveyed say they’ve been employed in a job requiring the technical skills learned at bootcamp, with an average salary increase of 50.5% or $23,724. The average starting salary of a bootcamp grad is $70,698.” One reason this is possible is the immersive bootcamp model, where students are present, full-time,
-
I work for Metis and I’m super proud of what we do, but this guide isn’t an ad for my company. I’m honestly not going to mention Metis very often. But if you really want to know, I think that we’re the best in the business for people interested in Data Science and for whom our immersive bootcamp model and cost structure works. ↩