Deep Learning Tips
I often find myself in roughly this situation:
I’ve done a lot of work to pre-process data, researched different DL architectures and selected one (or more), modified it so that it works well on my data. And now I’ve got a model that does well, but not quite as well as I want it to.
Below I’ll outline steps that I find very useful in this situation. Of course, more detail about how to get to that point is for another post. Also, I’m using Keras so many of these are specific to that tool, but they could absolutely be applied to other DL packages.
Clean up training code and improve logging.
My typical workflow when I’m building or tweaking a model by hand is to run Kears in a Jupyter notebook. This works fine if the entire pipeline runs in a few minutes but doesn’t work if I need to close my laptop while the pipeline is running. Jupyter often has trouble gracefully reconnecting and then I lose all the verbose info.
Porting my code into a self-contained python script allows me to connect to a machine over mosh and tmux, run the script, and then forget about it. This is handy on it’s own but it’ll be extremely handy when we get to the later tips.
The tools I use for this are:
keras.callbacks.CSVLogger(...)keras.callbacks.TensorBoard(...)keras.callbacks.ModelCheckpoint(..., save_best_only=True)
CSVLogger takes the output from verbose and stores it in a csv file for later. If you’re using tmux, it should be preserving your terminal log (and the verbose output) but csv puts all of that history data in a format where you can easily use it.
TensorBoard is super handy if you want to be able to monitor the progress of a long-running model from somewhere other than your terminal. I can access this from my iPad and it looks great!
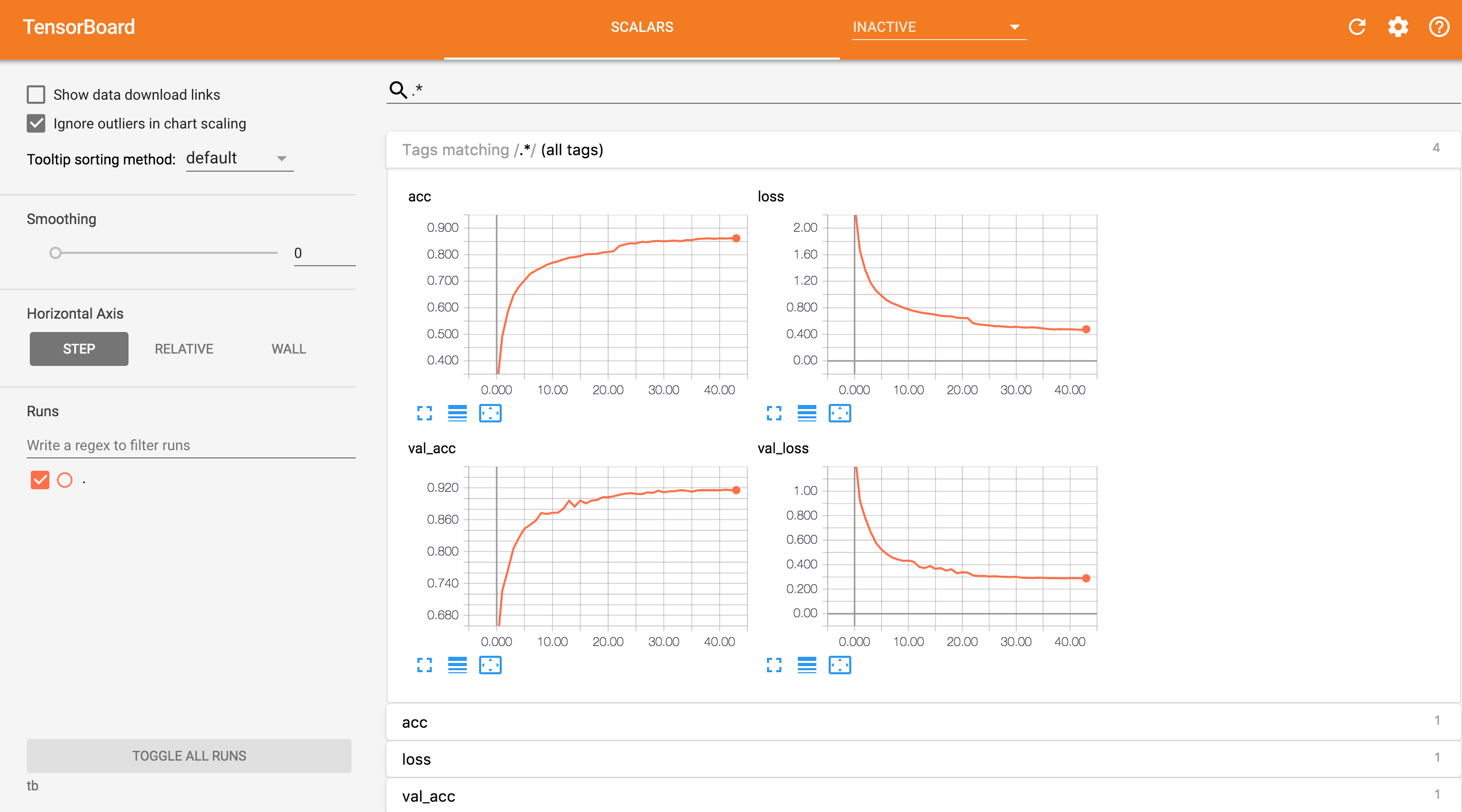
ModelCheckpoint saves your model every so often (you set the frequency as a parameter). This is nice on its own because it allows you to access a model that was trained in a script from anywhere (including my preferred tinkering environment, Jupyter). Even more than that, if you use save_best_only=True, then the script is automatically saving space by only saving the best performing model (you should youse val_loss or some other validation metric with this option).
Learning Rate Schedule
keras.callbacks.LearningRateSchedulerkeras.callbacks.ReduceLROnPlateauThis is my preference. I use this in conjunction with EarlyStopping and ModelCheckpoint all the time.
Use noise and other transformations to enlarge your datasets
- keras.preprocessing.image.ImageDataGenerator()
- Tensorflow blog discussing this with background noise
Optimize
There are many hyperparameters that can be optimized:
- Learning rate
- Dropout rate
- Preprocessing steps
- Different architectures (size and shape of layers as well as count) and parameters
- Regularizers and parameters
- Initializers and parameters
- and more!
These create an enormous space of possible models for which to test. My recommendation is to find something that works and then from that functioning model determine plausible options for the above hyperparameters. Then throw what you have into hyperopt.
- HyperOpt does this automatically. It’s poorly documented but fairly easy to use.